n8n node 병렬 실행의 어려움
최근에 사이드 프로젝트에서 n8n을 기술 스택으로 사용했다. n8n은 노코드 툴로서, 사용자들이 간단하게 설정하고 커스터마이징할 수 있도록 하는 목적으로 기술 스택으로 선택했다.
막상 써보니, n8n에서 “노드 몇 개를 동시에 돌리는 일”이 생각보다 쉽지 않았다.
예를 들어, webhook 노드를 쓰는 방법은 작업이 모두 완료되도록time.sleep같은
동작을 하는 노드를 사용해 타이밍 조절을 해야 하는 까다로움이 있다.
또 다른 방법으로는 n8n에서 제공해주는 main/worker 구조의 queue mode가 있지만,
이는 여러 워크플로우를 동시에 돌리기 위한 방식이지 하나의 워크플로우 내부에서 간단히 병렬 실행하고 싶은 내 목적과는 결이 달랐다.
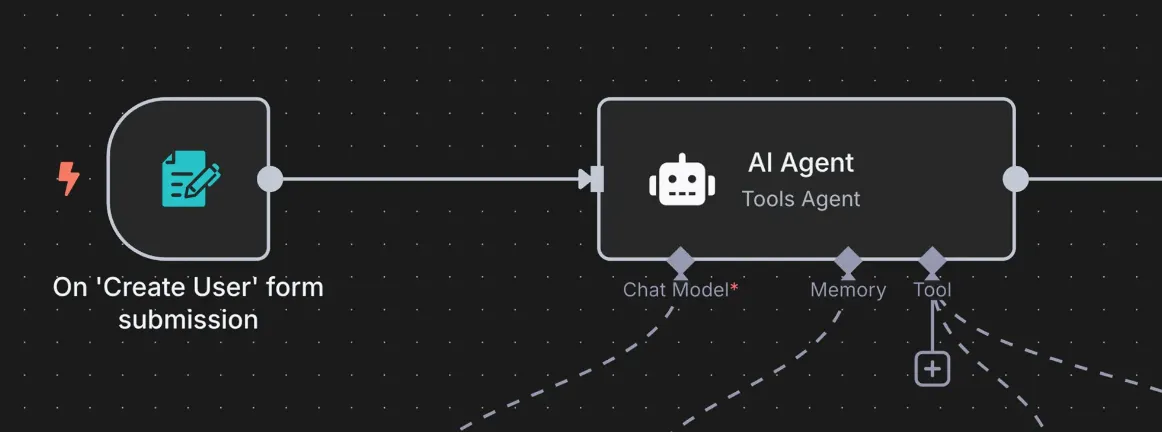
그래서 n8n에서 AI Agent를 병렬로 실행하고 싶다면, n8n의 AI Agent Node 대신 Code node에서 LangChain 프레임워크를 활용해서 직접 구현하는 것이 더 수월했다.
다만, LangChain에서 제공해주는 API 안에서도 병렬화에 한계가 있다.
문서를 살펴보니 “어디까지 병렬로 돌릴 수 있는지”가 내부 실행 모델 차원에서 이미 정해져 있었다.
그래서 이 글에서는 다음 질문을 다뤄보려고 한다.
LangChain은 어떤 내부 구현 때문에, 병렬 처리가 어디까지 가능한가
위에서 언급한 “LangChain”이라는 단어는 LangChain 프레임워크를 의미하며,
이 프레임워크는 LangChain, LangGraph 등 여러 패키지로 구성되어 있다. 공식 문서에 따르면, 세밀한 커스텀이 필요할 때는 LangChain보다 저수준인 LangGraph를 쓰라고 안내한다.
나 역시 AI Agent를 병렬로 사용할 목적때문에 LangGraph를 사용했다.
이후부터는 용어를 명확히 하기 위해, LangChain이 아니라 LangGraph라는 표현을 사용하려 한다.
왜 Google은 Pregel을 만들었을까
LangGraph에서 Graph를 이용한 대규모 병렬 연산을 위해 Google에서 만든 Pregel이라는 개념을 차용했다.
그래서 먼저, Google이 왜 Pregel이라는 시스템을 만들었는지부터 짚어볼 필요가 있다.
Google은 링크로 이루어진 인터넷에서 사람들에게 중요한 내용을 추출해 순위를 매겨야 했다.
문서를 정점, 링크를 엣지로 생각하면 인터넷은 거대한 그래프로 볼 수 있다.
그런데 기존의 MapReduce 알고리즘은 본질적으로 함수형 모델이다.
즉, 그래프 알고리즘을 여러 단계의 MapReduce로 표현하면, 각 단계마다 그래프의 전체 상태를 다음 단계로 전달해야 한다.
이는 더 많은 통신과 직렬화 오버헤드를 초래할 수 있다.
또한, 여러 MapReduce Job을 어떤 순서로 연결할지, 중간 결과를 어떤 형식으로 전달할지, 실패 시 어떻게 재시작할지 같은
Job 간 조율 로직에 대한 복잡도는 개발자가 직접 구현해야 했다.
개발자마다 구현이 제각각이면 전체 시스템 복잡도도 쉽게 증가할 수 있었다. 이 문제를 해결 하기 위한 일관된 표준이 필요했다.

그래서 Google은 다음 목표를 갖고 설계했다:
(1) 다양한 그래프 알고리즘을 자연스럽게 표현할 수 있을 것
(2) 값싼 다수의 머신으로 구성된 클러스터에서 확장 가능하고 장애 내성이 있게 동작할 것
Google에서 위 두가지를 위해 어떤 개념들을 구현했는지 살펴보자.
Pregel의 핵심 아이디어
한줄로 요약하면, Pregel은 동기식 메시지 전달 기반의 정점 중심 모델을 채택했다.
- Superstep
- 계산 -> 메시지 전송 -> 전역 동기화를 한 바퀴 도는 라운드 단위이다.
- 각 superstep에서 모든 활성 정점에 대해 같은 사용자 정의 함수가 동시에 호출된다.
- 장점 : 단계별 전체 상태 동기화로 디버깅이 비교적 쉽고, 장애 발생 시 checkpoint에서 재시도가 가능하다.
- 정점 (Vertex)
- 이전 superstep에서 자신에게 전송된 메시지를 수신하고, 다른 정점들에게 보낼 수 있다.
- 실행 중 정점과 간선을 동적으로 추가, 삭제할 수 있다.
- 장점 : 그래프 구조를 유연하게 표현할 수 있다.
LangGraph는 Pregel을 어떻게 썼나
이제 LangGraph가 위 Pregel의 개념을 어떻게 적용했는지 보자.
각 개념들이 1:1 대응되는 것은 아니고, 의미상 유사하다고 생각한 것들을 매핑했다.
Superstep -> Step (Plan/Execution/Update)
LangGraph의 실행은 하나의 step이 다음 세 단계로 나뉜다.
- plan
- 이번 단계에 실행할 actor를 결정한다.
- 초기 단계 : 그래프의 진입점을 의미하는 특수 channel을 구독한 actor들을 선택한다.
- 이후 단계 : 이전 step에서 업데이트된 channel을 구독한 actor들을 선택한다.
- execution
- 선택된 actor들을 병렬로 실행한다.
- 조건 : 모두 완료되거나, 하나가 실패하거나 또는 timeout에 도달할 때까지 실행한다.
- update
- 이번 step에서 actor들이 쓴 값을 channel 상태에 반영한다.
- 종료 조건 : plan 단계에서 선택된 actor가 없거나, step의 최대 수에 도달할 때까지 위 순환을 반복한다.
이 구조의 장점은 명확하다.
한 step이 끝날 때마다 상태가 딱 끊어지기 때문에,
지금 뭐가 실행 중이고, 어디서 실패했는지를 이해하기 쉽다.
또한, 장애 발생시 다시 체크포인트으로 돌아가 재시도를 할 수 있다.
반면, 모든 actor가 이 라운드를 마쳐야 다음 step으로 넘어갈 수 있기 때문에, 이 동기식 모델은 이후에 보게 될 한계의 원인이 되기도 한다.
Aggregator -> BinaryOperatorAggregator (channel)
- Pregel에서 aggregator는 전역 통신, 모니터링, 데이터 공유를 위한 요구에서 나온 개념이다.
- 각 정점이 superstep 동안 값을 하나씩 내고, 시스템이 이를 sum 같은 연산으로 줄여 전역 값을 만든 뒤, 다음 superstep에서 모든 정점이 그 값을 읽을 수 있게 한다.
- LangGraph에서 Aggreggator는 BinaryOperatorAggregate channel로 구현된다.
- ex.
total = BinaryOperatorAgregate(int, operator.add)
- ex.
Combiner -> (해당 없음)
- Pregel에서 Combiner는 전송/버퍼링해야 할 메세지 수를 줄이기 위한 최적화 목적을 가진다.
- aggregator와의 차이는 목적과 범위에 있다.
- combiner는 통신 비용을 줄이기 위한 로컬 최적화이고, 메세지가 네트워크를 타고 나가기 전 워커 수준에서 동작한다.
- aggregator는 하나의 전역 값 공유를 위한 메커니즘이고, 이미 각 정점에서 제출된 값을 모아서 “전역적인 하나의 값”으로 만드는 역할을 한다.
- LangGraph에서 pregel의 실행 모델을 차용하고 있지만, 주 사용 환경이 보통 단일 프로세스라서 그런지
Pregel처럼 분산 환경에서 네트워크 비용을 줄이기 위한 Combiner에 대응하는 개념은 보이지 않았다.
동적으로 그래프에 간선 추가 -> addConditionalEdge + Send API
- Pregel은 각 정점의
Compute()함수가 실행 도중 그래프에 새로운 정점/간선을 추가하거나 제거할 수 있다. - LangGraph의 addConditionalEdge와 Send API는 Pregel처럼 그래프 정의 자체를 바꾸지는 않지만,
특정 노드 실행 결과와 상태를 보고 “다음에 어느 노드로 흐름을 보낼지”를 런타임에 결정하는, 일시적인 edge 생성 역할을 한다.
function routeToAgents(state: typeof RouterState.State): Send[] { // 1. classifications 배열을 순회하며 각 항목마다 Send 객체 생성 // 2. c.source: 대상 노드 이름 (동적 라우팅 결정!) // 3. { query: c.query }: 해당 노드에 전달할 부분 상태 // 4. Send[] 반환 → Pregel이 다음 슈퍼스텝에서 병렬 실행 return state.classifications.map( (c) => new Send(c.source, { query: c.query }) );}
const workflow = new StateGraph(RouterState) ... .addConditionalEdges("classify", routeToAgents, ["github", "notion", "slack"]) .compile();지금까지 비교한 내용을 정리하면 아래 표와 같다.
| 구분 | Pregel | LangGraph |
|---|---|---|
| 처리 단위 | Superstep | Step (Plan / Execution / Update) |
| 계산 주체 | Vertex | Actor (PregelNode) |
| 통신 수단 | Message | Channel (LastValue, Topic, etc) |
| 실행 환경 | 분산 클러스터 (다수 머신) | 주로 단일 머신/프로세스 |
| 동기화 방식 | 전역 barrier 동기화 | 동기식 순환 (step barrier) |
| 그래프 구조 유연성 | 실행 중 정점/간선 동적 추가 | 정적 그래프 + 조건부 라우팅 (addConditionalEdge) |
| 장애 복구 | Checkpoint 기반 복구 | Checkpoint 기반 복구 |
실제로 원했던 병렬 Workflow
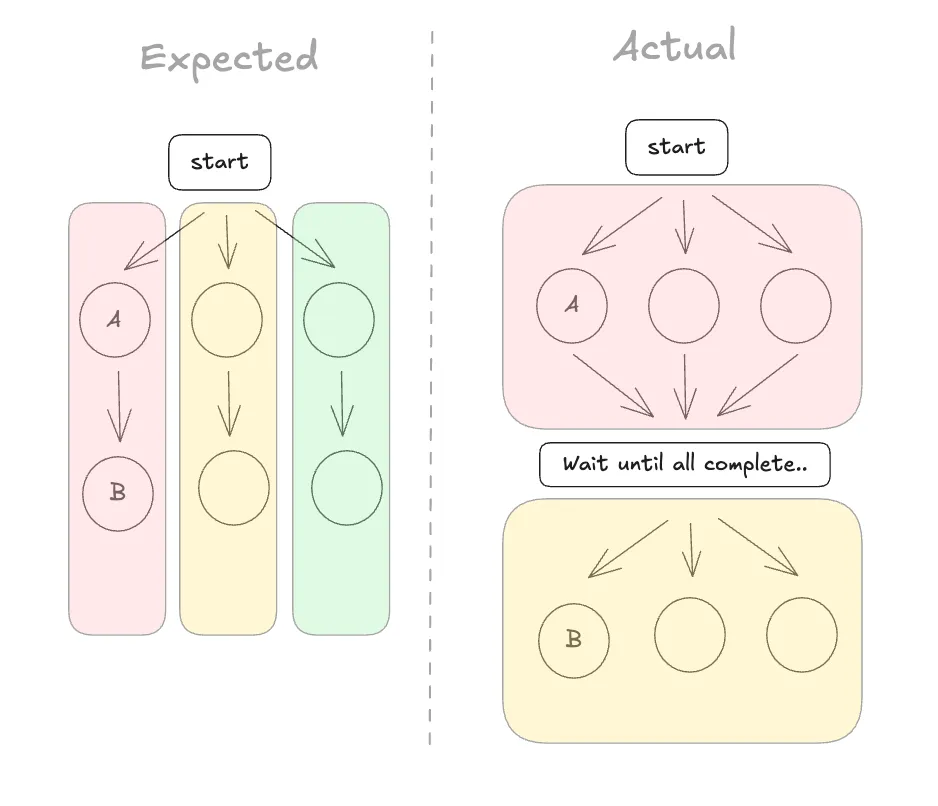 내가 구현하고 싶었던 구조는, 위의 왼쪽 그림처럼 하나의 그래프 안에서
A1 → B1, A2 → B2, A3 → B3가 느슨하게 동시에 흘러가는 형태였다.
내가 구현하고 싶었던 구조는, 위의 왼쪽 그림처럼 하나의 그래프 안에서
A1 → B1, A2 → B2, A3 → B3가 느슨하게 동시에 흘러가는 형태였다.
하지만 LangGraph의 step 모델에서는, 한 step에서 실행할 노드 집합이 먼저 정해지고, 그 집합이 모두 끝나야 다음 step으로 넘어간다.
Pregel 논문에서는, 정점 수가 머신 수보다 충분히 많다면 이런 동기식 모델도 비동기 시스템에 견줄 수 있다고 설명한다.
하지만 내 경우에는 병렬 실행 단위(스레드)에 비해 정점 수가 많지 않았고, 그러한 이점을 누릴 수는 없었다.
해결 방안 : 하나의 노드로 합치기
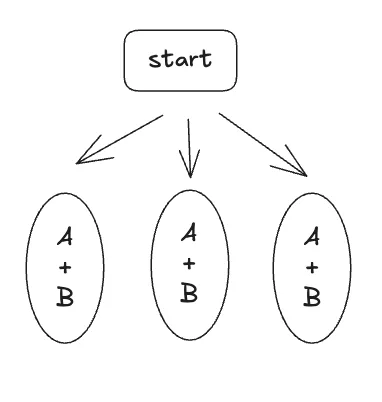
하나의 해결책은, A와 B를 하나의 Node로 합쳐서 실행하는 것이다.
하지만 이 방식은 B에서 에러가 나면, 이미 성공적으로 수행된 A까지 재시도해야 하는 문제가 있다.
따라서 우선 A와 B를 분리된 Node로 유지하기로 했다.
Pregel이 맞지 않는 경우도 있다
Pregel의 Bulk Synchronous Parallel(BSP) 모델은 대규모 그래프에 대한 반복적 배치 작업에 잘 맞는 모델이다.
하지만 실시간 추천 시스템과 같이, 사용자가 새로운 팔로우(Edge)를 자주 추가/삭제 하고,
주변만 점진적으로 연산해 빠르게 피드에 반영해야 하는 시나리오에는 잘 맞지 않는다.
마무리하며
얼마전에 무신사에서 정산 관련 기술블로그 글을 봤는데, Pregel의 정점처럼 결정적 계산이 가능한 단위로 로직을 쪼개고, 실패 시 그 단위의 시작 지점으로 돌아가 다시 실행하는 패턴을 사용하고 있었다.
위와 같이 순수 함수(pure function)는 같은 입력에 대해 항상 같은 결과를 내기 때문에, 재시도나 롤백 관점에서는 이상적인 단위다. 다만 분산 환경에서는, 이 함수들 사이에 필요한 모든 상태를 계속 전달해야 하고, 상태가 커질수록 직렬화·전송 비용이 커진다는 한계도 있다.
그래서 이런 환경에서는, 다음 상태를 어떻게 다음 순수 함수로 전달할 것인지를 정의하는 인터페이스가 미리 합의되어 있는지가 중요하다고 느꼈다.
예를 들어 Pregel은 ‘정점 값, 간선 값, 메시지’가 어떻게 오가고, 어디서 읽고 쓸 수 있는지 인터페이스를 API 수준에서 정해 두었기 때문에, 사용자는 그 위에서 결정적 계산 단위를 설계하고, 시스템은 그 단위를 중심으로 checkpointing과 재시도를 안정적으로 수행할 수 있다