찾아보게 된 이유
Quote
트래픽이 많은 날에는 많은 데이터가 쌓이게 되고, 해당 날짜 구간 로그를 저장하는 인덱스 조회 시 레이턴시가 증가하는 문제였습니다.
…
로그 수집용 인덱스(Timeseries)와 달리 Data Stream 기반으로 인덱스 템플릿을 구성하여 더 빠른 성능을 내도록 하였으며 …
위 문장을 기술 블로그에서 읽고, Data Stream이 어떤 부분이 성능이 더 좋은지, 왜 해당 부분에서 더 좋은지를 찾으며 알게 된 내용을 정리했다.
용어 정리
✅ Index Template
- 특정 패턴(logs-, metrics-)에 맞는 인덱스가 생성될 때 미리 정의한 설정(매핑, 설정, ILM 등)을 자동으로 적용하는 템플릿
✅ ILM (Index Lifecycle Management)
- 인덱스의 수명 주기를 자동으로 관리해주는 기능
- ex. 7일이 지난 인덱스는 read-only로 전환, 5GB가 넘는 인덱스는 롤오버(새로운 인덱스로 전환) 등
✅ Backing Indices
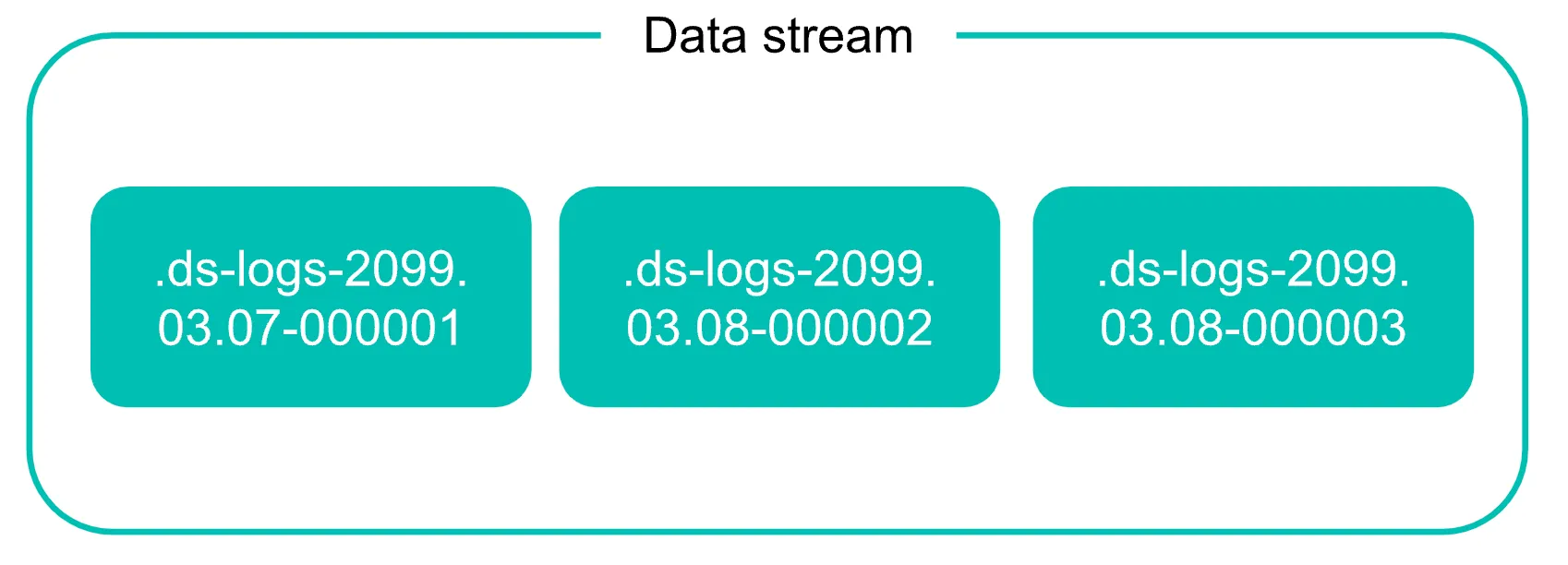
- Data Stream은 데이터를 물리적으로 저장할 때 하나의 인덱스가 아니라, 내부적으로 여러 개의 인덱스를 시점(time)이나 용량 기준으로 분리하여 저장
- 사용자는 몰라도 되지만, 실제로는 logs-web-000001, logs-web-000002 이런 식으로 인덱스들이 생성됨
✅ Time series data stream (TSDS)
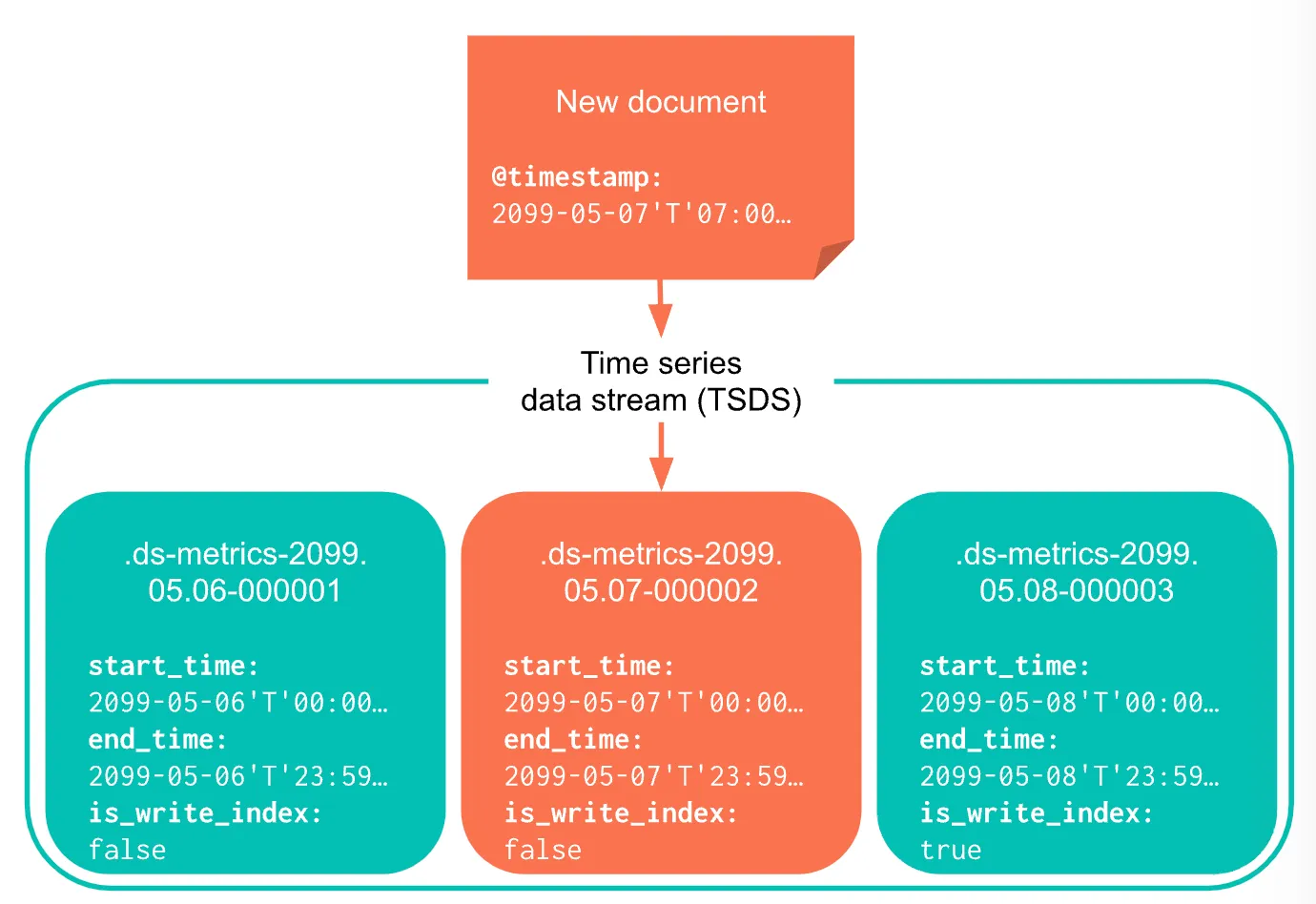
- 시계열 데이터를 저장할 때 성능 및 저장 효율 면에서 최적화 되어있다.
- 일반적인 Data stream 과의 차이점 중 하나는 TSDS는 일정 기간별로, 일반적인 Data Stream은 특정 age 또는 사이즈별로 인덱싱이 적용된다.
이해한 내용
- 기술 블로그에 따르면, Time series와 일반 Data stream 간에 성능 차이가 발생했다. Time series는 일정한 시간 구간 단위로 인덱스가 분할되는 반면, 일반 Data stream은 데이터 크기별로 인덱스가 분할될 수 있다. 이로 인해 트래픽이 몰린 기간의 데이터 조회 시 Data stream의 조회 범위가 더 작아져 결과적으로 조회 성능이 향상되었다고 이해했다.
다음에 해보면 좋을 것
- 이 링크 참고해서 실습해보기