시작하기 전
Andrej Karpathy라는 분의 Deep Dive into LLMs like ChatGPT 영상을 보고 인상 깊었던 부분을 흐름별로 요약하고, LLM을 활용한 오픈 소스(AI 코드리뷰 자동화) 코드를 분석한 내용을 담았다.
(1)편은 사전학습과 사후학습, (2)편은 강화학습으로 이루어진다.
이 문서는 영상에서 소개된 LLM의 작동 원리와 실제 소스코드의 분석을 바탕으로,
- LLM이 텍스트를 어떻게 이해하고 예측하는지
- LLM을 사용할 때 왜 환각(사실과 다른 내용을 말하는 현상)과 맞춤법 부정확 등 같은 현상이 일어나는지
- 오픈소스(AI 코드 리뷰 자동화 도구)에서는 어떻게 LLM을 활용하고 보완하는지
등의 내용들을 설명한다.
LLM은 “확률적 예측 시스템” 이다.
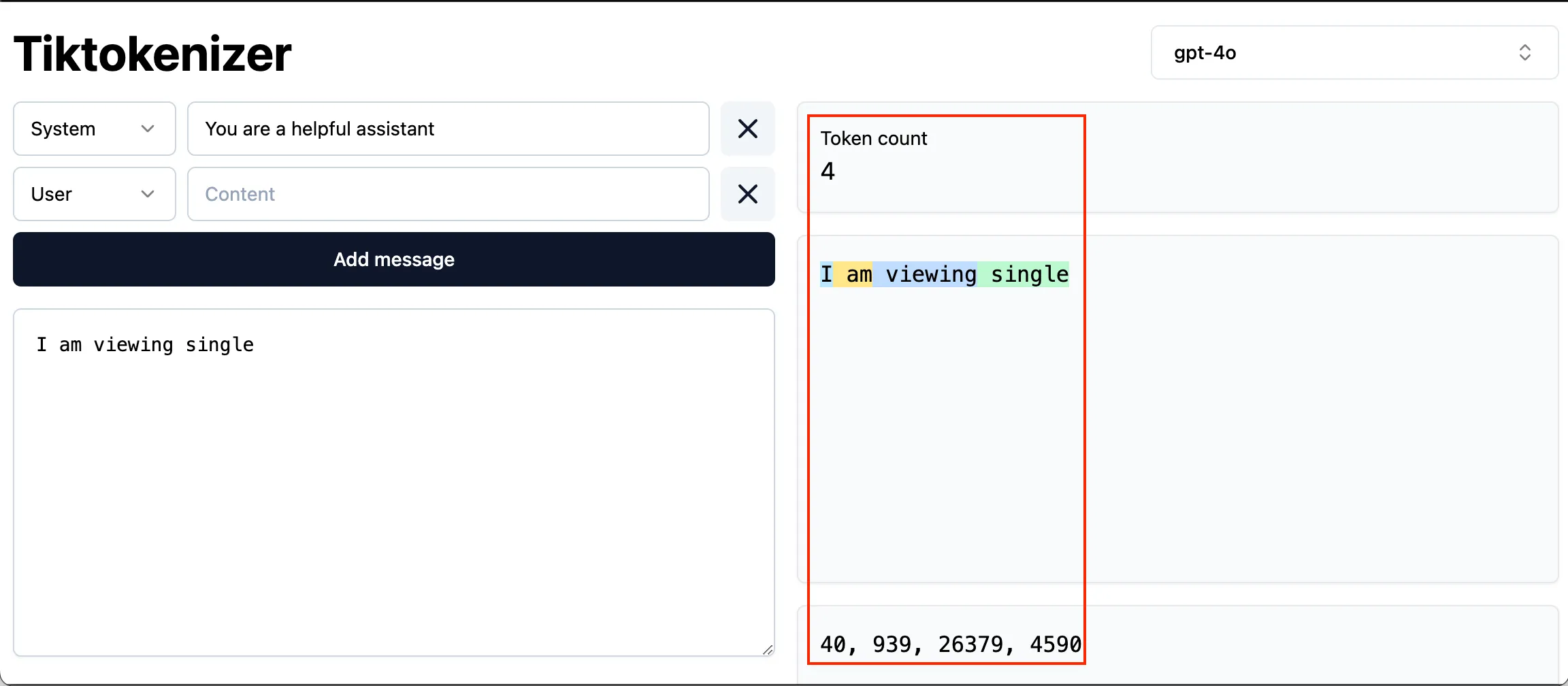
I am viewing signle …
LLM을 한 문장으로 정의하면 위 문장같은 텍스트가 주어졌을 때 다음 텍스트를 예측하는 확률적 시스템이라고 말할 수 있다.
이제 다음 단어를 예측하기 위해 어떠한 작업들이 안 보이는 곳에서 이루어지는지 살펴보자
LLM이 보는 세상은 “토큰”으로 이루어져 있다.
디지털 세계에서는 결국 모든 글자는 0과 1로 나타내어진다. 이진수들을 8개씩 묶어 2^8, 즉 256(0~255)가지의 조합이 가능하다. 8자리씩 묶는 규칙을 사용하면 디지털 환경에서 표현할 수 있는 문자에는 한계가 있다.
예를 들어, 알파벳 소문자 ‘v’는 8비트 이진수로 01110110이며, 이는 10진수로 118이라는 기호에 해당한다.
그런데 LLM의 목적인 다음에 올 내용을 예측하는 것을 다시 상기시켜보자.
I am viewing single 다음에 올 단어를 예측을 하기 위해서는 I, a, m, v, i, e, w…보다는 I, am, viewing, single 단위로 쪼갰을 때 다음 단어를 예측하는 것이 좀 더 유의미한 통계 데이터를 얻을 수 있을 것이다.
따라서, 자주 등장하는 패턴을 인식해 viewing 같은 단어에 0~255를 제외한 256부터 기호를 붙인다. 이렇게 묶인 것들을 토큰이라고 부른다.
토큰을 LLM 서비스에서는 어떻게 사용하는가
LLM마다 최대 토큰 수는 한정되어 있기 때문에, 이걸 신경쓰면서 LLM을 사용해야 한다.
그렇다면 AI 코드 리뷰 자동화 서비스에서는 최대 토큰을 어떻게 다루었을까.
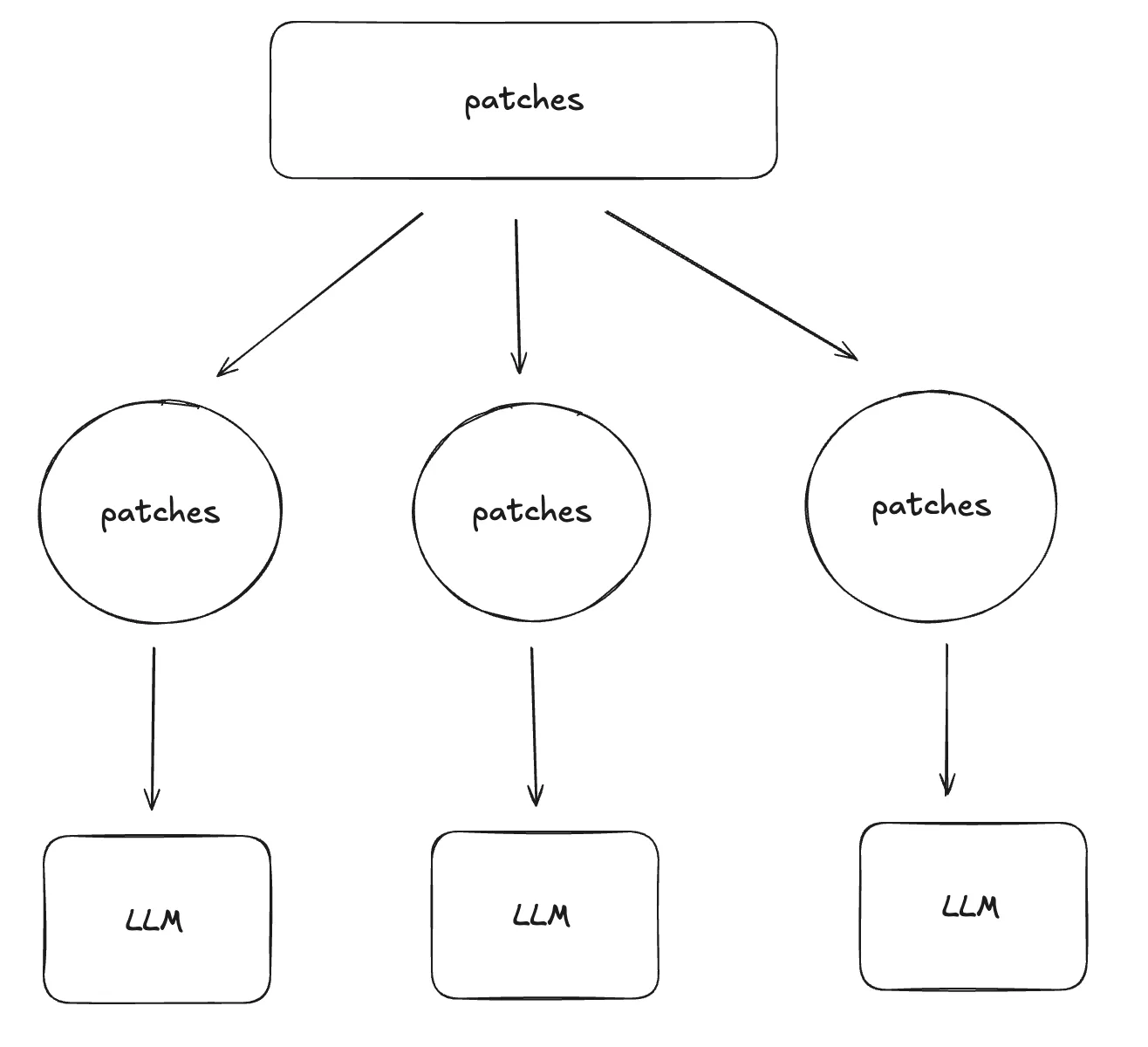
AI를 이용한 코드 리뷰 자동화 오픈 소스 툴인 pr-agent는 프롬프트가 최대 토큰을 넘는다면, 최대 토큰 + 버퍼만큼 분할해서 병렬 처리를 진행한다.
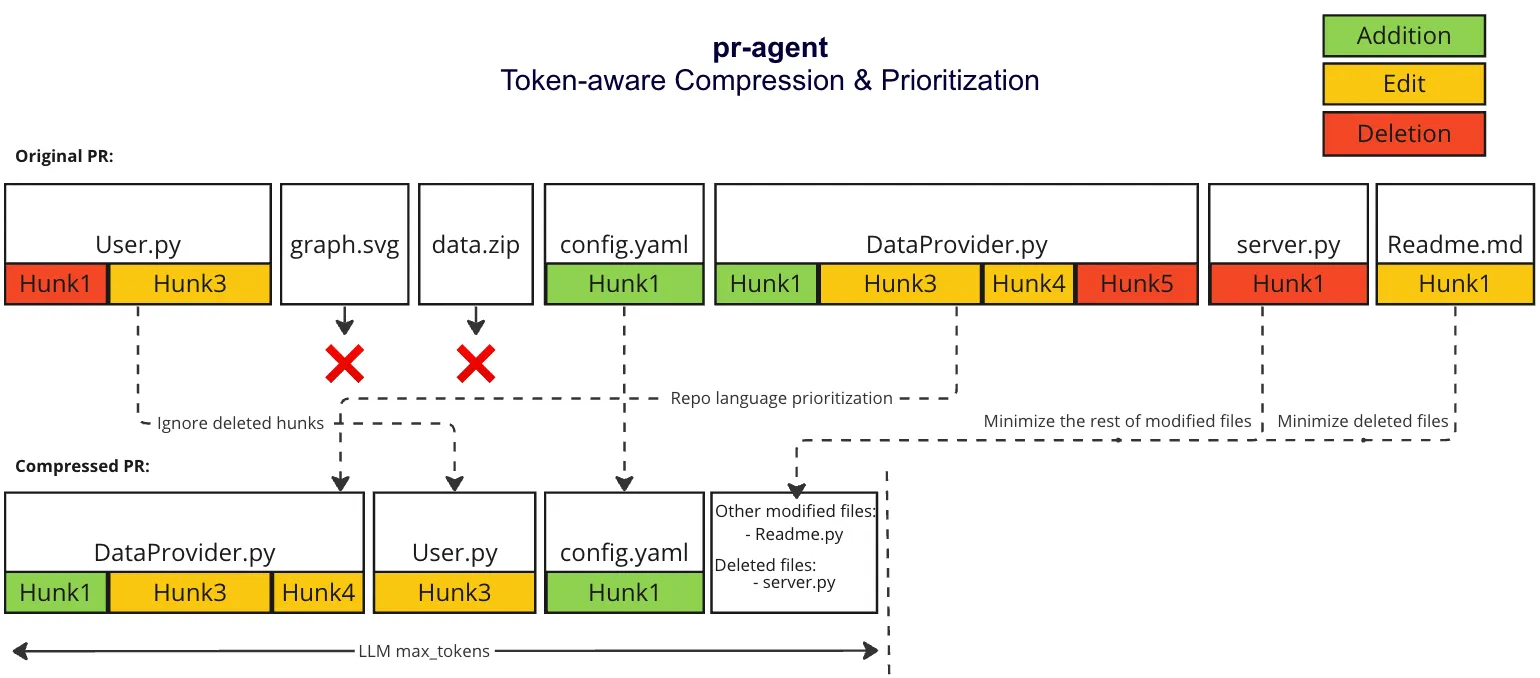
또한, 토큰수 절약을 위해 binary 파일이나 삭제만 있는 코드 변경 내역을 생략하는 등의 토큰 압축화 알고리즘을 진행한다.
이제 실제 코드를 살펴보자.
pr-agent에서 토큰 수를 구할 때 OpenAI에서 만든 오픈소스 토크나이저인 tiktoken을 이용해 Encoder 인스턴스를 만들고 TokenHandler에서 사용한다.
from tiktoken import encoding_for_model, get_encoding
class TokenEncoder: _encoder_instance = None _model = None ...
@classmethod def get_token_encoder(cls): ... cls._encoder_instance = encoding_for_model(cls._model) \ if "gpt" in cls._model else get_encoding("o200k_base") return cls._encoder_instance토큰화 알고리즘을 공개하지 않은 LLM(ex. claude) 같은 경우는 다른 도구를 이용해 토큰을 센다.
class TokenHandler: def __init__(self, pr=None, vars: dict = {}, system="", user=""): self.encoder = TokenEncoder.get_token_encoder()
def count_tokens(self, patch: str, force_accurate=False) -> int: encoder_estimate = len(self.encoder.encode(patch, disallowed_special=()))
if 'claude' in model and get_settings(use_context=False).get('anthropic.key'): return self.calc_claude_tokens(patch) ...
def calc_claude_tokens(self, patch): client = anthropic.Anthropic( api_key=get_settings(use_context=False).get('anthropic.key') ) ... response = client.messages.count_tokens(...)토큰으로 세상을 보기 때문에 가지는 LLM의 한계
LLM은 글자 단위가 아닌 토큰으로 텍스트를 인식한다. 따라서, 맞춤법이나 특정 문자의 개수를 세는 데에 취약하다. 특정 문자의 개수를 세는 것과 같은 작업은 외부 도구인 코드를 이용하도록 하는 것이 정확한 답변을 얻을 수 있다.
학습 데이터셋을 신경망에 입력하여 나온 기본 모델
우선 AI 어시스턴트를 만들기 이전에 기본 모델을 만들어야 한다.
아래와 같은 인터넷 문서를 크롤링한 데이터와 같은 데이터셋을 신경망에 학습시킨다.
학습을 하면서, 나온 손실값을 바탕으로 신경망의 가중치와 매개변수가 업데이트되고 다음 피드백을 위한 학습 루프가 돈다.

위의 학습을 토대로 기본 모델을 얻을 수 있다. 이 기본 모델은 아직 어시스턴트에 가깝지 않다.
기본 모델은 인터넷 데이터를 손실 압축해 학습한 확률적 토큰 예측 시스템이다.
기본 모델을 어시스턴트로 만들기 위한 대화 데이터셋
사람들이 원하는 건 질문을 하면 답변을 해주는 어시스턴트이므로, 기본 모델은 아직 미완성에 가깝다.
따라서 어시스턴트를 만들기 위해 많은 대화 데이터셋을 신경망에 입력한다.
여기서 대화같은 구조를 토큰으로 변환하는 규칙이 필요하다.
LLM마다 다른데 OpenAI의 경우 <|im_start|>, <|im_sep|> 등과 같은 특수 토큰들이 토큰 텍스트 사이에 삽입되어 모델이 대화 차례의 시작을 인식하게 한다.
어시스턴트는 사람과 대화를 하기 때문에 필요한 데이터셋의 시작은 사람들이 만든 레이블링된 데이터이다.
따라서 ChatGPT와 같은 LLM은 마법 같은 AI가 아닌, 사람이 작성한 지침을 모방하는 통계적 시스템이다.
어시스턴트를 만드는 데이터셋만 기본모델과 다를 뿐, 알고리즘적으로는 동일하다.
데이터셋의 구성에 따른 LLM의 한계
하지만 데이터셋을 신경망에 넣을 때 주의해야 하는 점이 있다. 우선, 데이터셋의 구성으로 가질 수 있는 두 가지 한계를 보자.
1. 환각 현상
첫째, 사실이 아닌 정보를 그럴듯하게 대답하는 환각 현상이 있다. 왜 그런 일이 일어날까? 가령 “A는 누구인가요?”라는 질문이 있을 때, 해당 스타일의 질문에 모른다고 답변하는 대화 데이터셋이 학습할 때 포함되어 있지 않기 때문이다. 따라서 환각 현상의 개선책은 “모른다”라고 답변하는 대화 데이터셋을 넣는 것이다.
그렇다면 LLM이 아는 것과 모르는 것을 어떻게 구분할 수 있을까?
먼저, 특정 문서를 LLM에게 직접 입력해 질문과 올바른 답변에 관한 데이터를 구성한다. 그리고 특정 문서를 주지 않고 질문을 신경망에 입력했을 때, 올바른 답변이 나오지 않으면 해당 질문을 “모른다”고 답변하는 데이터를 학습 데이터셋에 추가한다.
LLM을 사용하는 입장에서는 어떻게 환각 현상을 개선할 수 있을까?
LLM이 직접 참조할 수 있도록 배경이 되는 데이터를 직접 주거나, 웹 검색을 통해 사실에 기반해 답변하도록 하게 하는 것이다. 예를 들어, 오만과 편견 1장을 요약해달라고 할 때, 실제 데이터를 주는 것이 좀 더 사실에 가까운 요약을 얻을 수 있을 것이다.
환각 현상 방지 - 문맥을 더 주기 위한 노력
AI 코드 리뷰 자동화 툴에서는 어떻게 LLM에게 더 자세한 문맥을 줄 수 있을까
Git에서는 하나의 연속된 변경 블록을 hunk라고 부른다. 아래처럼 hunk에서는 고정적으로 코드 변경 사항에서 변경되지 않은 앞뒤 3줄의 내용이 포함되어 있다.
또한, 아래에서 hunk header를 알리는 @@ 구분자가 있는 라인을 보면 메서드의 이름이 표시된 걸 볼 수 있다. hunk header는 변경된 위치, 줄 수, 그리고 선택적으로 클래스, 함수 이름과 같은 정보들을 포함한다.
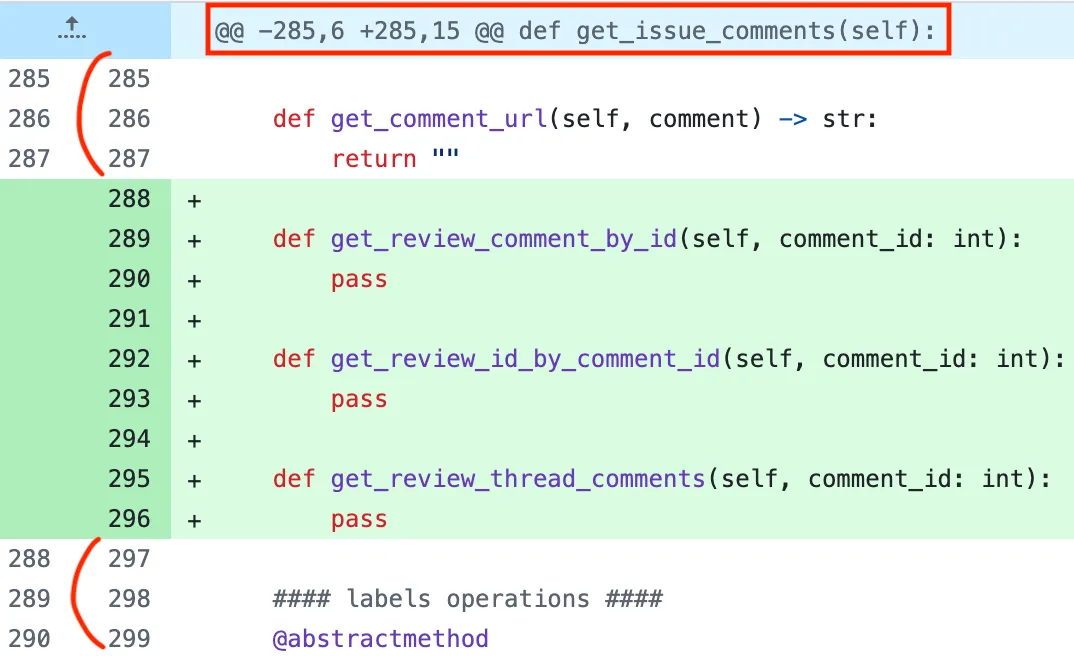
AI 코드 리뷰 자동화 툴에서는 코드 변경에 적합한 문맥을 위해 가능하다면 함수/클래스를 감싸고 있는 코드를 주는 것이 좋다고 보았다. 따라서 앞에서 설정값만큼 확장한 다음 hunk header에 있는 함수/클래스 이름이 포함되어 있다면 코드를 좀 더 확장하여 LLM에게 제공한다.
def process_patch_lines(...): patch_extra_lines_before_dynamic = get_settings().config.\ max_extra_lines_before_dynamic_context ... # 정규식을 이용해 section_header(=hunk_hader)의 값을 추출한다. RE_HUNK_HEADER = re.compile(r"^@@ -(\d+)(?:,(\d+))? \+(\d+)(?:,(\d+))? @@[ ]?(.*)") for i, line in enumerate(patch_lines): if line.startswith('@@'): match = RE_HUNK_HEADER.match(line) if match: section_header, size1, size2, start1, start2 = extract_hunk_headers(match) extended_start1, extended_size1, extended_start2, extended_size2 = \ _calc_context_limits(patch_extra_lines_before_dynamic)
# section_header가 코드 라인에 포함되어 있으면 확장한다. if section_header in line: # 컨텍스트 시작 지점 조정 extended_start1, extended_start2 = \ extended_start1 + i, extended_start2 + i break ...2. 자기 인식을 하지 못함
둘째, LLM은 자기 인식을 하지 못하는 한계를 가지고 있다. 예를 들어, LLM 초기 모델에서는 넌 어떤 모델이냐는 질문에 제대로 된 답변을 하지 못할 수 있다. 학습 과정에서 LLM은 암묵적으로 도움을 주는 비서 역할이라는 페르소나를 자연스럽게 학습하지만, 내가 어떤 모델인지에 대한 질문에는 데이터가 없으면 대답할 수 없다.
따라서, 학습 데이터셋이나 사용자에게 노출되지 않는 시스템 메세지에 LLM에 대한 설명을 넣어야 대답할 수 있게 된다.
하지만 이는 억지로 붙인 데이터일 뿐, 사람처럼 자기 인식이 깊게 자리 잡은 것은 아니다.
단방향 토큰 시퀀스 처리 방식과 대화 데이터셋 구성의 관계
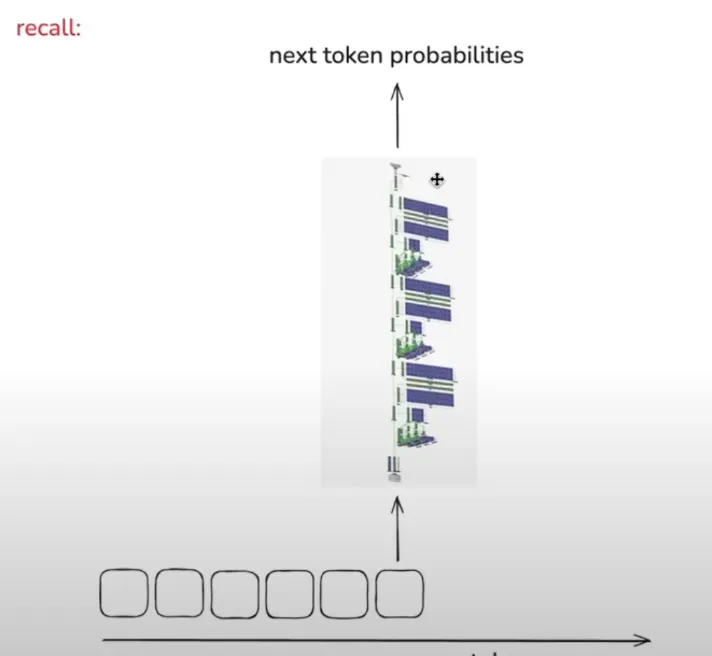
LLM은 단방향 토큰 시퀀스 처리 방식을 사용한다.
아래 이미지를 보며 알 수 있는 것은 왼쪽에서 오른쪽으로 일차원적으로 쌓여나가며 다음 토큰이 예측되는 시스템이라는 것과, 예측에서 일어나는 계산 층의 수가 유한하다는 것이다.
위 사실을 떠올리며 아래 프롬프트에서 어떤 답변이 좋은 대화터셋일지 생각해보자.
“철수가 사과 3개와 오렌지 2개를 샀고 13,000원이 나왔다. 각 오렌지는 2000원씩 한다. 그렇다면 사과는 얼마일까?” 라는 질문에
- A 답변 : “답은 3000원이다. 왜냐하면 2개의 오렌지는 4000원이므로 3개의 사과는 9000원이다. 따라서 한 개의 사과는 3000원이다.”
- B 답변 : “2개의 오렌지는 4000원이므로 3개의 사과는 9000원이다. 9000/3 = 3000. 따라서 답은 3000원이다.”
어떤 답변이 좋은 대화 데이터셋일까?
계산 층의 수가 유한하기 때문에 각 토큰에서 수행되는 연산량은 한정되어 있다.
따라서 중간 결과를 구하는 식으로 답변을 천천히 하면, 여러 토큰에 걸쳐서 연산량을 분산할 수 있다.
A 답변은 초기 몇 개 토큰에서 모든 연산을 수행하도록 하는 것이기 때문에, 잘못된 답변이 나올 수 있다.
따라서 B 답변으로 대화 데이터셋을 구성하는 것이 좋을 수 있다.
환각 현상을 개선하기 위해 웹 검색을 사용하게 한 것처럼, 수학 계산을 할 때 코드를 쓰라고 외부 도구를 사용하게끔 하는 것도 정확한 답변을 얻기에 좋다.
요약
이 때까지 대규모 언어 모델(LLM)의 주요 훈련 단계 두 가지와 한계를 살펴보았다.
-
- 사전 훈련: 인터넷 문서 (input) -> 기본 모델 (인터넷 문서 시뮬레이터) (output)
-
- 후속 훈련: 대화 데이터셋 (input) -> 어시스턴트
LLM의 잘못된 답변을 방지하기 위해서는 웹 검색, 코드같은 외부 도구를 사용하고 직접 내용을 컨텍스트에 포함시키는 게 좋다.
느낀 점
pr-agent라는 AI 코드 리뷰 자동화 툴 코드를 분석하며 느낀 점은 한정된 토큰 내에서 LLM에게 어떻게 자세한 문맥을 줄 것인지를 고민해야 한다는 것이다. 이를 위해 JSON 대신 YAML 형식을 사용하거나, 필요에 따라 문맥을 동적으로 확장하려는 시도들이 눈에 띄었다.
또한 이 과정을 통해 창의성에 대해서도 생각해보게 되었다. LLM은 결국 확률 기반의 시스템이기 때문에, 낮은 확률의 응답이 선택될 때 오히려 전에 없던 새로운 결과물이 나오는 경우가 있다. 나는 이런 상황이 일종의 창의성으로 볼 수 있지 않을까 하는 생각이 들었다.
이와 관련해 지인과 대화를 나눈 적이 있었는데, 그 지인은 창의성을 단순히 결과물의 새로움으로 보지 않고, 그에 담긴 맥락과 의도가 중요하다고 말했다. 예컨대, 미술사에서 새로운 사조가 등장했을 때 그것을 창의적이라고 평가하는 이유는 단순한 새로움이 아니라, 그 시대와 문화 속에서 어떤 의도를 갖고 나타났는지를 보기 때문이라는 것이다.
그런 점에서 LLM의 temperature와 같은 값을 조절하여 나온 결과는, 맥락과 의도가 결여된 단순한 확률적 변형일 수 있기 때문에, 그것을 창의적이라고 보기는 어렵다는 의견이였다.
이 대화를 통해 나는, 결국 창의성을 구성하는 핵심은 ‘맥락’과 ‘의도’이며, 이는 LLM을 활용할 때에도 마찬가지라고 느꼈다.